
Medvlmoe: sparse mixture of experts vision language model for multi-pathology medical image diagnosis
Keywords:
Vision Language Model, Mixture of Experts, Medical Image Diagnosis, Cross-Modal Fusion, Radiological AI, Multi Pathology Classification.Abstract
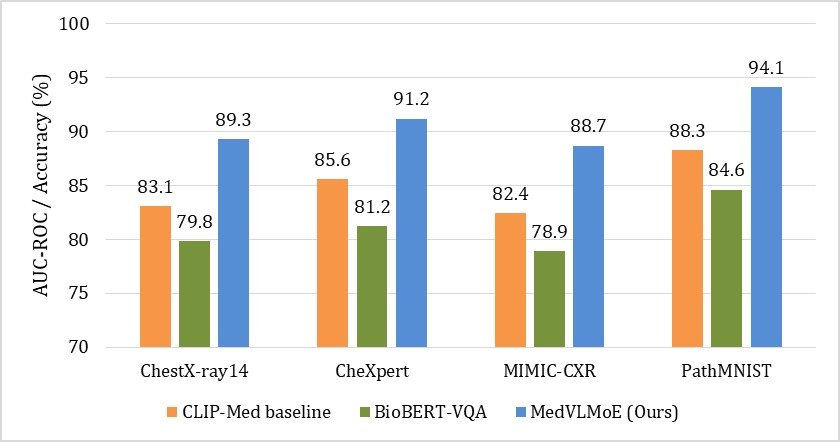
Existing Vision Language Models use a single shared representation space where the visually complex signatures of various disease classes cannot be captured. Existing Vision Language Models have a single shared representation space, and are unable to represent the visually complex signatures of different disease classes. To address the above challenges, this paper introduces MedVLMoE, a sparse Mixture of Experts (MoE) Vision Language Model to route fused image-text representations to disease experts' networks. It is a dual-stream encoder consisting of ViT-L/14 for radiological image feature and BioGPT for clinical text, with modality-specific position encodings to encode the position, and learn a cross-modal fusion attention module that connects the two streams. The sparse MoE module (K=8 experts, Top-2 routing) allows to specialize on diseases without the need of explicit supervision by experts, which is enforced by a load-balancing auxiliary loss. Experiments are shown to outperform the best baseline (CLIP-Med) by 3.7–6.3% in terms of the AUC-ROC metric on five medical imaging benchmarks (ChestX-ray14, CheXpert, MIMIC-CXR, PathMNIST, RetinaMNIST). The activation analysis was used by experts to interpretively explain the behaviour of the MoE modules in clinical AI systems, and emergent disease-specific routing specialization was identified.
Published
How to Cite
Issue
Section
Copyright (c) 2025 Dr. Inam Ullah Khan

This work is licensed under a Creative Commons Attribution 4.0 International License.

