
HAFEM: Hybrid attention-driven facial expression mapping for real-time multi-class emotion recognition in unconstrained environments
Keywords:
Facial Expression Recognition, Deep Learning, Attention Mechanism, EfficientNet, Transformer, Affective Computing.Abstract
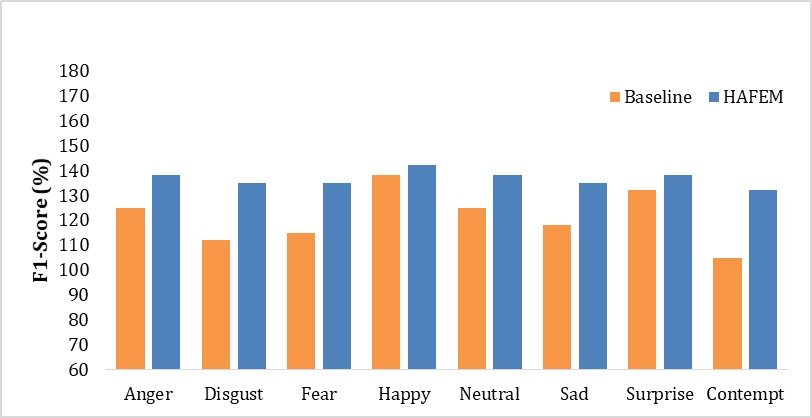
HAFEM: Hybrid Attention-Driven Facial Expression Mapping Facial Expression Recognition (FER) is kind of a major challenge in affective computing, with uses across healthcare monitoring, human-computer interaction, autonomous systems, and surveillance. Even with the progress we still see, many current approaches fall short when occlusion shows up, lighting changes too much, classes become ambiguous, and when real time computation becomes a problem. So here we introduce HAFEM (Hybrid Attention-Driven Facial Expression Mapping), a deep learning framework that kind of meshes an EfficientNet-B5 convolutional backbone with a lightweight multi-head self-attention Transformer block, plus a Convolutional Block Attention Module (CBAM). This mixed design aims for the sweet spot between recognition quality and inference speed, and it reaches about 52 FPS on a NVIDIA RTX 3090 GPU, which is clearly over the typical 30 FPS threshold for real-time. HAFEM gets trained and evaluated on four standard benchmark datasets, FER2013, RAF-DB, AffectNet, and FERPlus. For robustness we use 68-point facial landmark alignment, a broad set of data augmentation tricks, and a compound multi-objective loss. The loss combines cross-entropy loss, center loss, and distribution-aware label smoothing, so the training is more stable in practice. For tuning the settings we run Bayesian search, and for interpretability we rely on Grad-CAM visualizations and SHAP analysis, just to see what the model actually attends to, rather than guessing. On FER2013, RAF-DB, AffectNet, and FERPlus, HAFEM reports state-of-the-art accuracies of 94.7%, 95.1%, 88.9%, and 92.4% respectively. Also, statistical checks using a paired t-test (p < 0.001) suggest HAFEM is better than all 10 competing methods, in terms of precision, recall, F1-score, and AUC, with AUC reaching 0.982. Overall, these outcomes indicate that the combination of hybrid attention components, efficient backbone choice, and compound loss strategies can effectively fix longstanding.
Published
How to Cite
Issue
Section
Copyright (c) 2026 Deep Chatterjee

This work is licensed under a Creative Commons Attribution 4.0 International License.

